Inteligência Artificial não enxerga como os humanos - e isso não é bom
Redação do Site Inovação Tecnológica - 26/09/2022
[Imagem: Nicholas Baker et al. - 10.1016/j.isci.2022.104913]
Ilusões de óptica artificiais
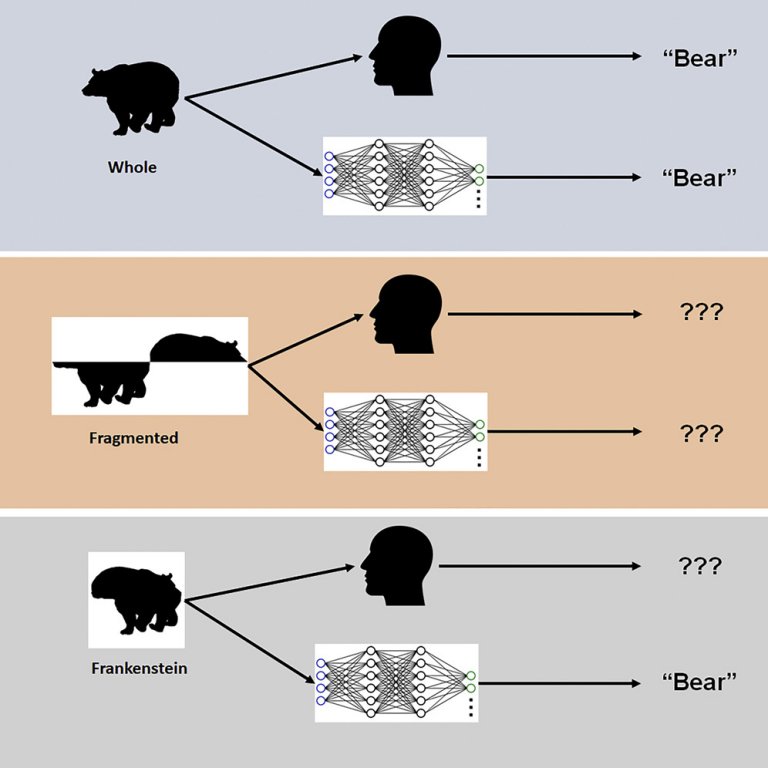
As redes neurais convolucionais profundas (RNCPs) não veem os objetos da maneira como os humanos veem - e isso pode ser perigoso em aplicações da inteligência artificial no mundo real.
Esta é a conclusão dos professores Nicholas Baker e James Elder, da Universidade de York, no Canadá, que descobriram que as técnicas mais usadas no processamento de imagens para visão artificial - ou visão de máquina - não usam o mecanismo da visão humana, conhecido como percepção configurável de forma.
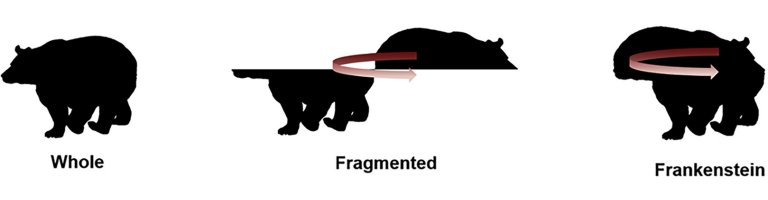
Os dois pesquisadores usaram estímulos visuais, conhecidos como "frankensteins", para explorar como o cérebro humano e as redes neurais processam as propriedades dos objetos.
"Frankensteins são simplesmente objetos que foram desmontados e montados de forma errada," explicou Elder. "Como resultado, eles têm todos as características locais corretas, mas nos lugares errados."
A grande descoberta é que, enquanto o sistema visual humano é confundido pelos frankensteins, as RNCPs não são, revelando uma insensibilidade da visão artificial às propriedades dos objetos e oferecendo respostas incorretas em suas tentativas de identificação.
"Nossos resultados explicam por que modelos de IA profundos falham sob certas condições, e apontam para a necessidade de considerar tarefas além do reconhecimento de objetos para entender o processamento visual no cérebro," disse Elder. "Esses modelos profundos tendem a usar 'atalhos' ao resolver tarefas complexas de reconhecimento. Embora esses atalhos possam funcionar em muitos casos, eles podem ser perigosos em algumas das aplicações de IA no mundo real em que estamos trabalhando atualmente com nossos parceiros do setor e do governo."
[Imagem: Nicholas Baker et al. - 10.1016/j.isci.2022.104913]
Problema por resolver
Uma das aplicações das redes neurais que preocupa os dois cientistas são os sistemas de segurança de trânsito e de visão artificial dos veículos autônomos: "Os objetos em uma cena de trânsito movimentado - os veículos, bicicletas e pedestres - obstruem uns aos outros e chegam aos olhos de um motorista como um amontoado de fragmentos desconectados," explica Elder.
O cérebro humano "desconstrói" esse emaranhado de informações visuais e consegue rapidamente distinguir um ciclista entrando rapidamente na via por detrás de outro carro.
Mas a inteligência artificial não consegue fazer isso, vendo apenas fragmentos isolados - um carro com um tronco humano no teto, neste exemplo - que não serão adequadamente identificados, eventualmente colocando em risco os usuários mais vulneráveis no trânsito.
De acordo com os pesquisadores, as modificações no treinamento e na arquitetura destinadas a tornar essas redes neurais convolucionais profundas mais parecidas com o cérebro não resultaram no processamento similar ao humano, e nenhuma das redes foi capaz de prever com precisão as avaliações humanas dos objetos.
"Nós especulamos que, para corresponder à sensibilidade configural humana, as redes devem ser treinadas para resolver uma gama mais ampla de tarefas de objetos, além do reconhecimento de categorias," observou Elder.
Artigo: Deep learning models fail to capture the configural nature of human shape perception
Autores: Nicholas Baker, James H. Elder
Revista: iScience
DOI: 10.1016/j.isci.2022.104913
Nenhum comentário:
Postar um comentário